SaulLM-7B: A pioneering Large Language Model for Law
A large language model (LLM) tailored for understanding and processing legal documents.
| Paper | arXiv |
| Models | Equall/Saul-Base Equall/Saul-Instruct-v1 |
| Datasets | Equall/legalbench_instruct Equall/perplexity_evaluation |
| Company | Equall.ai |
Summary
What’s the idea in a sentence or two?
- 7 billion parameters LLM based on Mistral architecture trained on English legal corpus of over 30 billion tokens for legal text comprehension and generation.
What’s the motivation as framed by the authors?
- Lack of LLMs for legal domain
- By pretraining a LLM on dedicated legal corpora, the LLM will be able to comprehend the complexities of legal documents but also to adapt to the evolving nature of legal discourse.
How do they attempt to solve it?
- Family of legal LLMs: SaulLM-7B & SaulLM-7B-Instruct
- Improved evaluation protocol for legal LLMs: LegalBench-Instruct
- Model, Evaluation Code & Licensing: Models released under MIT license
What is the main contribution of the paper?
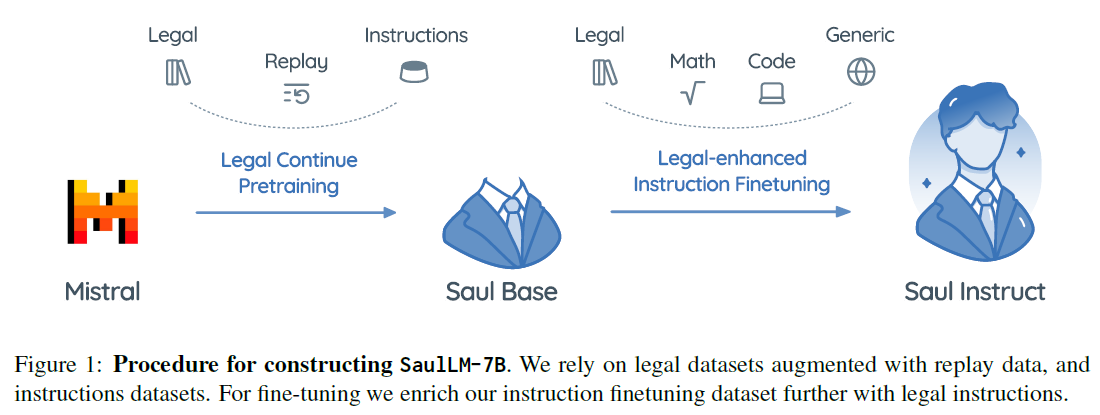
- Mistral continued pretraining on legal corpus of 30 billion tokens.
- Dataset Composition
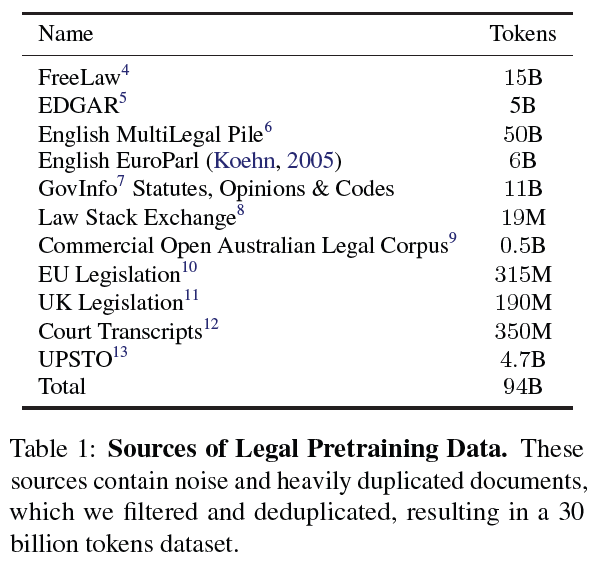
- Replay Sources:
- Reduce the risk of catastrophic forgetting by incorporating data from the prior training distribution.
- Data from
Wikipedia,StackExchange, andGitHub, comprising roughly 2% of the final training mix sampled from SlimPajama was included.
- Instruction Sources:
- Authors found inclusion of conversational data during pretraining to be beneficial.
- Data from Super Natural Instruction and FLAN was included.
- Dataset Composition
- Support user requests and conversational interaction by instruction fine-tuning on a dataset comprising of 600K instructions. The dataset involves 2 key components:
- Generic (non-legal) instructions: SlimOrca, MetaMathQA, UltraChat and Glaive Code Assistant v2
- Legal instructions: Multi-turn conversations generated using Mistral-7B-instruct model i.e.,
[User] Legal text 🡆 [Assistant] Response 🡆 [User] Provide reasoning 🡆 [Assistant] ...
- Additional step of aligning the model with human preference was not required due to lack of meaningful improvement in performance.
How do they measure success?
- Benchmark
- Perplexity Measurement
- Contracts dataset - EDGAR (Q1 of 2024)
- Legal descisions dataset - ICSID court decisions (after October 2023)
- Legislation focused dataset - US bills submitted before the House or Senate (after October 2023)
- Party submissions dataset - Texas briefs submitted (after October 2023)
- LegalBench-Instruct
- Formatting the LegalBench dataset by,
- removing distracting few-shot exmaples
- concluding with a specific instruction for the model to generate tags
- Formatting the LegalBench dataset by,
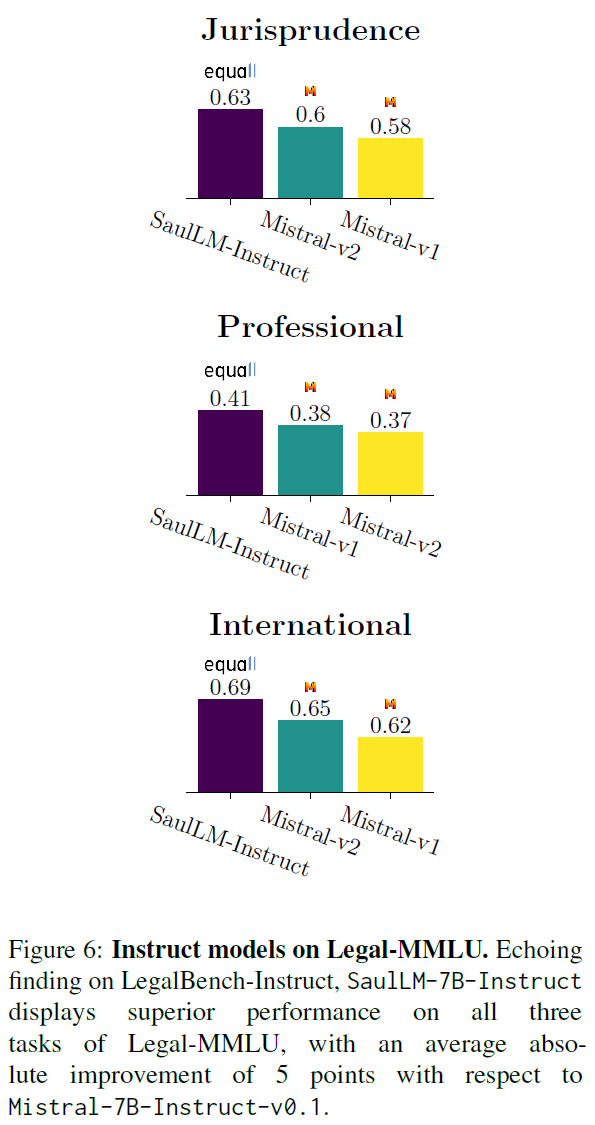
- MMLU
- International law (120 examples)
- Professional law (1500 examples)
- Jurisprudence (110 examples)
- Perplexity Measurement
- Metrics
- Balanced accuracy
Were they successful?
-
Perplexity Measurement
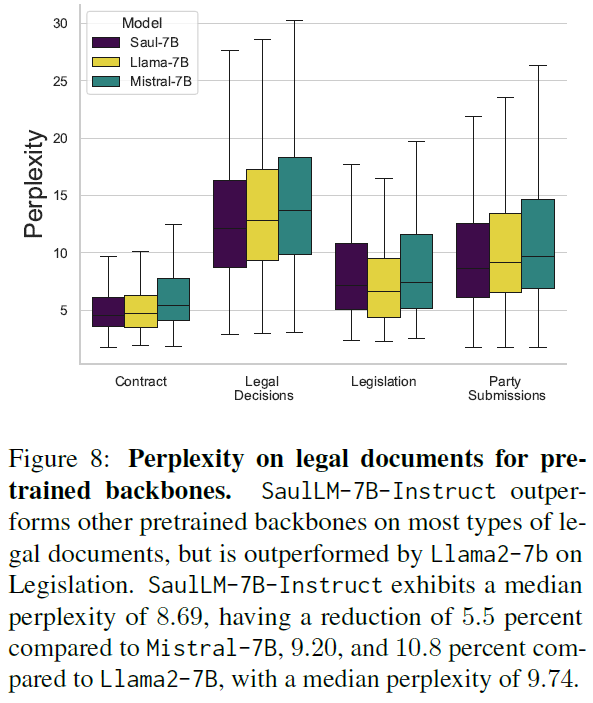
-
LegalBench-Instruct
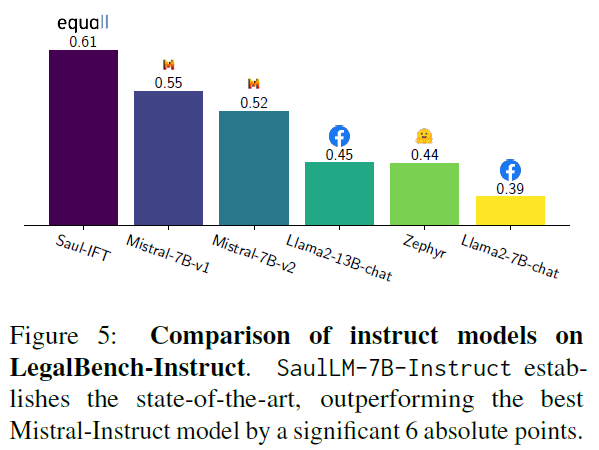
-
MMLU
This post is licensed under
CC BY 4.0
by the author.